
When systems experience temporary failures — like network delays or overloaded servers — retries are necessary. However, retrying too quickly can make things worse, creating more congestion. Exponential backoff helps by gradually increasing the wait time between retries. But if multiple clients retry at the same intervals, they can cause another traffic surge. This is where jitter (randomness in delay) becomes useful.
In this blog, we’ll explain how jitter improves system reliability, its impact on high-read and high-write systems
How Exponential Backoff Works
When a request fails, exponential backoff gradually increases the wait time before each retry:
- Retry 1: Wait 100ms
- Retry 2: Wait 200ms
- Retry 3: Wait 400ms
To prevent excessive retries, a maximum retry limit is typically set. For example, after three retries, the request is marked as failed, and an error is returned.
This approach helps reduce the load on a failing system by spacing out retries. However, if many clients retry at fixed intervals (e.g., exactly at 100ms, 200ms, etc.), they may end up overwhelming the system again when their retries align. This is known as the thundering herd problem, where a surge of simultaneous retry attempts puts additional strain on an already struggling system.
How Jitter Helps
Jitter prevents synchronized retries by adding randomness to wait times. Instead of every client waiting exactly 100ms, 200ms, 400ms, they wait for slightly different intervals. This spreads out retries, reducing system strain.
Types of Jitter:
- Full Jitter: Random delay between
0andmaxBackoff. - Equal Jitter: A minimum delay plus a random component.
- Decorrelated Jitter: Delay is based on the previous wait time plus randomness.
Jitter in High-Read and High-Write Systems
High-Read Systems (e.g., Caching, Search Engines)
- When multiple users request the same data simultaneously, it can overload caching servers.
- If cached data expires at the same time, many clients may attempt to refresh it simultaneously, creating spikes in traffic.
- Introducing jitter in cache refresh times ensures that requests are spread out, reducing sudden surges in load.
High-Write Systems (e.g., Databases, Log Aggregators)
- When multiple clients write data at the same time, it can slow down database performance.
- Adding jitter to write operations helps distribute writes more evenly, preventing sudden performance drops.
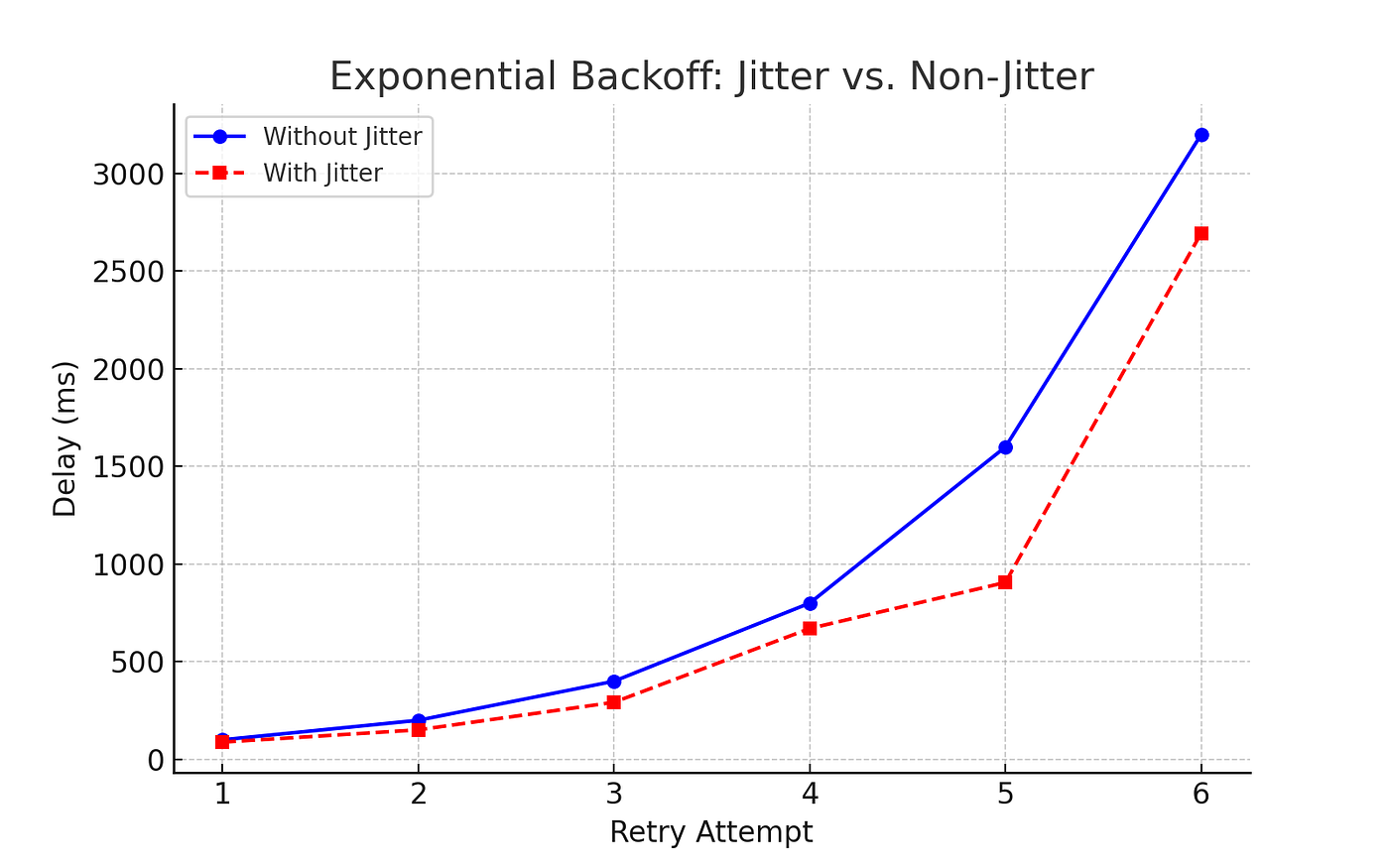
Understanding Jitter Through a Graph
To visualize the impact of jitter, consider these two cases:
1. Exponential Backoff Without Jitter
When all clients retry at fixed intervals, they cause spikes in traffic.
2. Exponential Backoff With Jitter
By adding randomness, retries are spread out, preventing synchronisation.
🛠 Key Takeaway: Jitter smooths out retry behavior, improving stability.
Reference link-
- AWS Best Practices for Exponential Backoff: AWS Docs
Conclusion
Exponential backoff with jitter is a simple but effective way to handle retries. It prevents synchronized retries from overwhelming a system and improves reliability.
- Full Jitter is great for unpredictable failures.
- Equal Jitter balances response time and randomness.
By applying jitter, systems become more stable, efficient, and resilient in real-world conditions 🚀.
Thank you for reading! 😊
Stay connected and stay updated on the latest trends in technology by connecting with me on LinkedIn.
For more insightful articles and updates, feel free to visit my Medium profile.
Happy coding and keep innovating! 🚀



Leave a Reply